Computational Philosophy
Computational philosophy uses computational models, simulations and data-driven methods to investigate philosophical questions. A computational model makes assumptions explicit, represents their consequences precisely, and allows us to explore cases that would be difficult or impossible to analyse by hand. The resulting simulations do not replace philosophical arguments. However, they can establish possibility results, reveal unexpected consequences, test the robustness of informal reasoning, and clarify which assumptions are responsible for a result.
Models as philosophical instruments
Models can function as philosophical instruments. They help us move from loose verbal intuitions to explicit assumptions and precisely stated consequences. In many philosophical domains, especially where multiple agents interact over time, informal reasoning alone can miss important structural possibilities. Computational models help reveal those possibilities.
They are useful for at least four reasons:
- Demonstrating possibility. A model can show that a phenomenon can arise under a given set of assumptions.
- Identifying mechanisms. It can reveal how local rules or informational structures generate broader social or epistemic outcomes.
- Testing robustness. Parameters and assumptions can be varied systematically to determine whether a result depends on a narrow special case.
- Clarifying concepts. Implementing a model forces us to specify exactly what is being modelled and why.
Computational philosophy is therefore not a replacement for traditional philosophical argument. It is a way of extending it.
Bayesian networks and rational belief change
One major strand of my research uses Bayesian networks to study belief, evidence and rational belief change.
A joint probability distribution assigns probabilities to every possible combination of values taken by a set of variables. Suppose that three binary variables represent whether a treatment is effective, whether a clinical study is reliable, and whether a patient recovers. The joint probability distribution assigns a probability to each possible combination of these outcomes. It therefore represents not only the agent's confidence in each proposition separately, but also how those propositions are probabilistically related.
As the number of variables increases, a full joint probability distribution quickly becomes difficult to specify and interpret. A Bayesian network provides a more structured representation. Its nodes represent variables or hypotheses, while its directed edges represent probabilistic dependencies. The network factorises the joint probability distribution into a set of local conditional relationships. Instead of specifying every possible combination directly, we specify how each variable depends on a smaller set of relevant variables.
This makes the structure of the agent's beliefs visible and allows the consequences of new evidence to propagate through the network.

This framework moves beyond models in which agents hold only one isolated opinion. Real agents hold many beliefs, and those beliefs influence how they interpret evidence. A judgement about a scientific result may depend on wider beliefs about institutions, expertise, causal mechanisms, source reliability or the trustworthiness of particular methods.
My research uses Bayesian networks to investigate rational belief polarisation. These models show how apparently pathological outcomes, such as persistent disagreement or increasing divergence, can arise even when agents update rationally on the same evidence.
This is philosophically important. It shows that polarisation does not depend entirely on familiar non-ideal factors such as cognitive bias, irrationality, misinformation, selective exposure or unequal access to evidence. Even after those factors are removed from a model, structurally rational agents may still polarise.
The models are useful in two related ways. First, they provide a how-possible explanation of polarisation by making a possible mechanism explicit. Evidence about one proposition propagates through a wider structure of connected beliefs, and agents with different starting points can therefore respond differently to the same evidence.
Second, the models illuminate the normative structure of rational belief change. They describe how a Bayesian agent should revise its beliefs, conditional on its prior probabilities and its beliefs about the relations among hypotheses. This does not imply that the priors are justified, that the probabilistic model is correct, or that the resulting polarisation is socially desirable. It shows that divergence can be compatible with coherent rational updating.
This work extends from belief polarisation to factionalisation. A population factionalises when several beliefs become increasingly correlated across the population, producing groups whose members agree across multiple issues rather than diverging only on a single question. Read more about rational belief polarisation and factionalisation.
Social networks and scientific communities
A second strand of computational philosophy studies inquiry as a social process. Belief change does not happen in isolation. It occurs in communities structured by communication networks, trust relations, institutions and incentives.
This area is often called network epistemology. Agents are represented as nodes in a social network, while links represent channels of communication, trust or information exchange. The structure of the network can then be varied to examine how it affects the beliefs of the community.

Social-network and agent-based models can be used to study consensus, disagreement, polarisation, the spread of misinformation, the division of cognitive labour, and the organisation of scientific communities.
One important example is the Zollman effect. Under some conditions, less densely connected scientific communities can perform better epistemically because temporary local independence helps preserve theoretical diversity for longer. Highly connected communities may converge too quickly on an initially promising but inferior approach. This is not a general argument against communication. It shows that the epistemic value of communication depends on the structure of the network, the reliability of the evidence and the dynamics of inquiry.
My work in this area focuses especially on network epistemology, rational polarisation, factionalisation, scientific gatekeeping, and the behaviour of scientific and social communities under different informational conditions.
These models are deliberately idealised. Their purpose is not to reproduce every detail of a real scientific community, but to isolate particular mechanisms and determine how those mechanisms behave across controlled cases.
Signalling games, communication and understanding
Computational philosophy also provides powerful tools for thinking about communication and representation. A central framework here is the signalling game.
David Lewis introduced signalling games as part of his analysis of convention. A sender observes a state of the world and sends a signal to a receiver, who must choose an appropriate action. Brian Skyrms and others later developed evolutionary and learning-based models of how signalling systems can emerge without being designed in advance.
These models make it possible to investigate the origins of meaning, the stability of communication systems, and the conditions under which agents develop shared representations.

My work uses signalling-game models to investigate communication and understanding, especially compositional understanding. A system does more than associate isolated signals with isolated states when it can combine representational elements systematically and apply them successfully in novel cases. Computational models allow us to examine when such structured systems emerge, how stable they are, and how communication depends on the organisation of the agents' internal representations.
You can explore these models using my interactive signalling-game visualisers: classic Skyrms-Lewis signalling games and the evolution of compositionality.
Artificial intelligence as object and method
Artificial intelligence matters to computational philosophy in two distinct ways.
First, AI is itself an object of philosophical investigation. Questions about understanding, representation, explanation and epistemic reliability arise naturally in connection with machine-learning systems. My research on AI and understanding asks what it would take for a system to do more than predict successfully, and whether learned internal structure can support genuine understanding.
This connects naturally to ideas about learned representations and latent spaces. Modern machine-learning systems often transform complex data into high-dimensional internal representations that support prediction, classification or control. The geometry of these latent spaces may capture real regularities in the target domain, but it may also be opaque, unstable or poorly aligned with the variables used in human scientific explanations.
Second, AI and related computational techniques can be used as methods within philosophy. Natural-language processing can support the analysis of corpora far larger than a researcher could inspect manually. Techniques such as named-entity recognition, topic modelling, semantic similarity, clustering and document classification can help reveal structure in philosophical, scientific, historical or public texts.
Word embeddings and other representation-learning methods can also be used to study how concepts cluster, how their use varies across contexts, and how patterns of discourse change over time.
Machine learning can therefore reveal structure in complex datasets and support new forms of philosophical model construction. But these methods introduce methodological risks. A model may rely on unstable shortcuts, reproduce biases in its training data, or organise information in ways that are difficult to interpret. A latent representation may be useful for prediction without corresponding neatly to the categories that matter for explanation.
High predictive accuracy does not by itself establish that the model has identified the right structure. The philosophical task is to determine what these systems represent, what their success demonstrates, and under which conditions their learned representations support genuine understanding.
Manifold learning and scientific structure
Computational philosophy also intersects with philosophy of science through work on modelling, abstraction and representation. My work on manifold learning and effective theory building explores how machine-learning methods can recover useful higher-level structure from complex data.
The familiar Swiss-roll example provides a simple illustration. Data may appear to occupy a complicated form in a high-dimensional space while in fact lying close to a lower-dimensional manifold. A manifold-learning algorithm can sometimes recover a more revealing representation of that underlying structure.
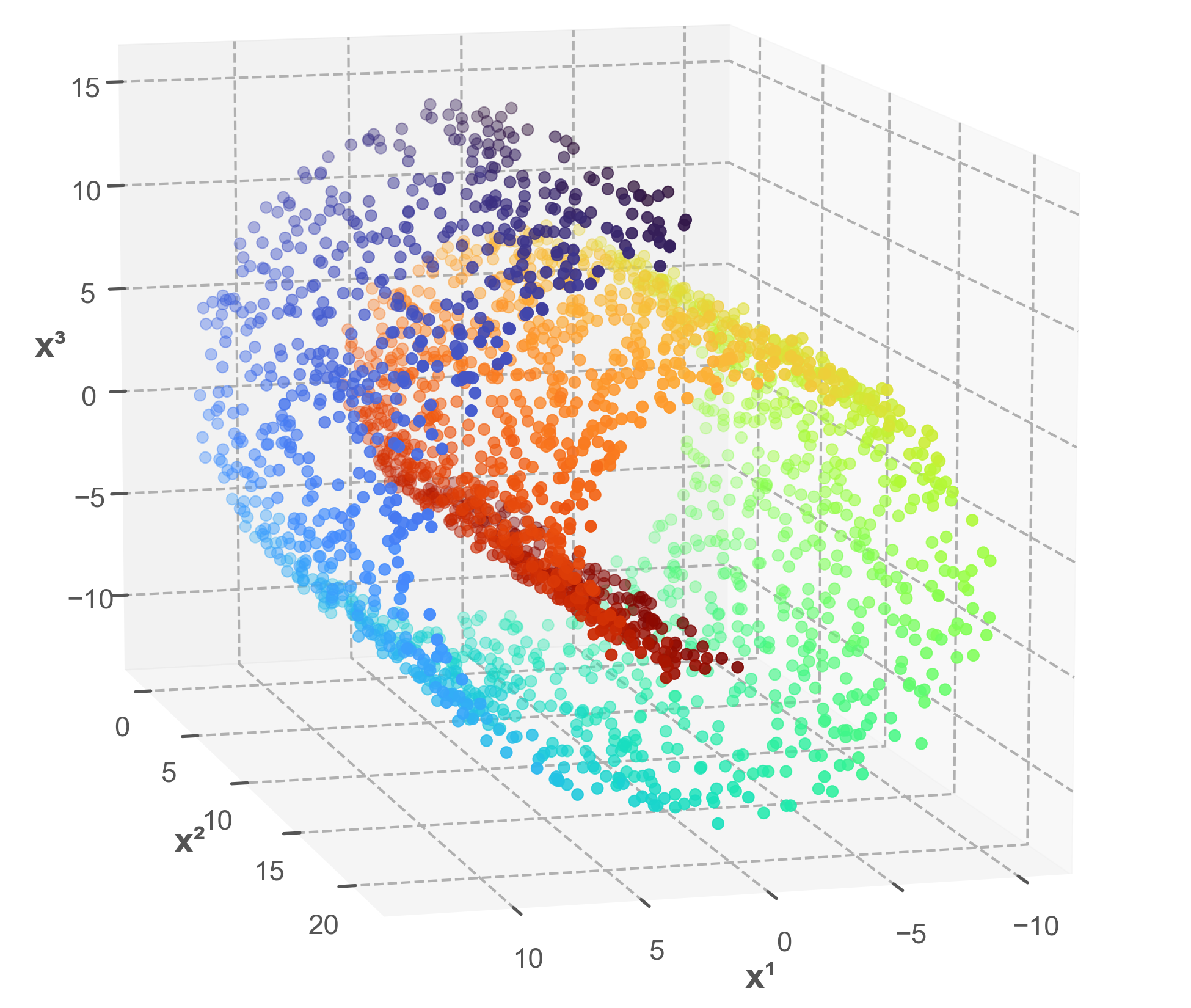
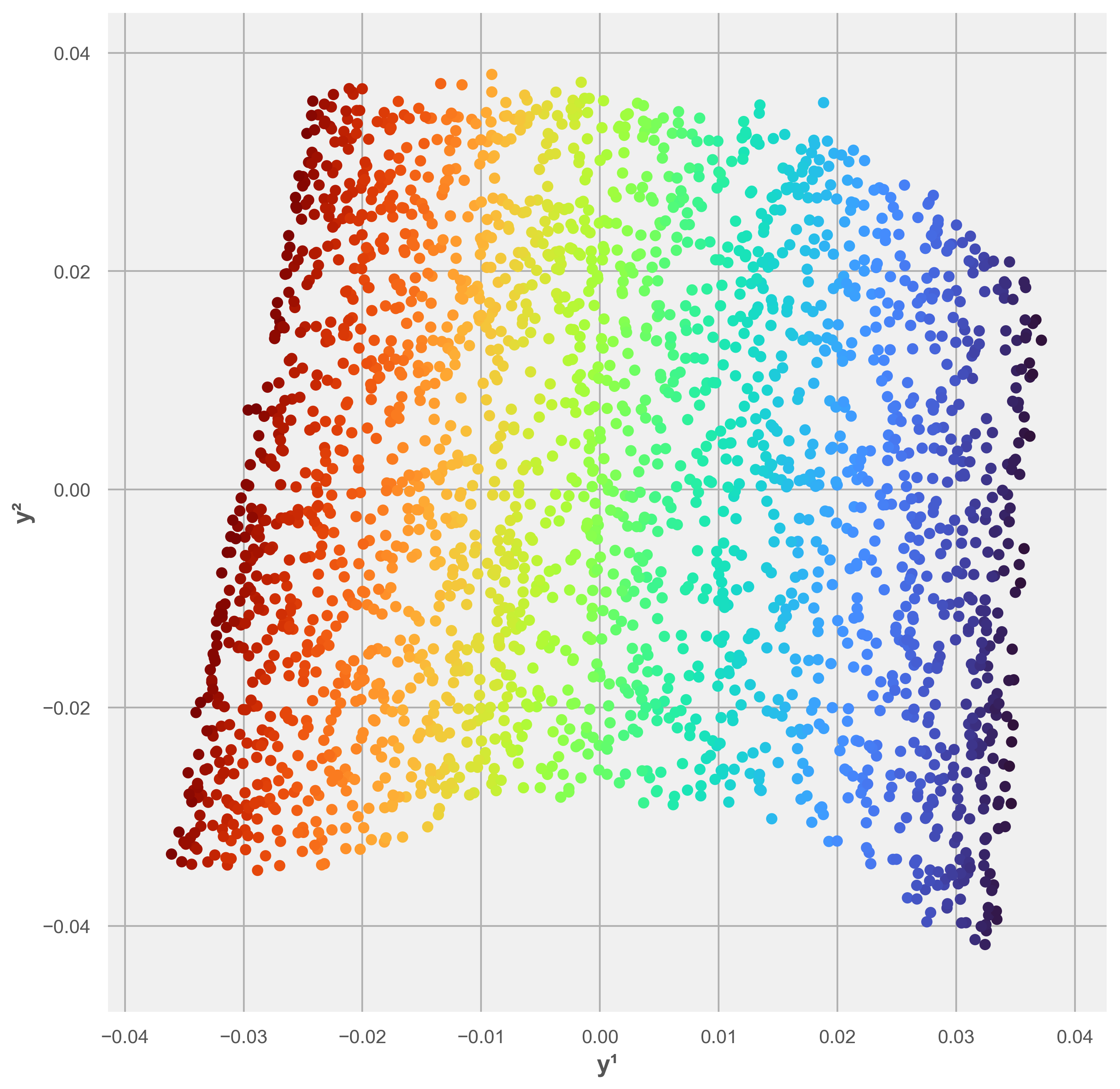
Philosophically, this bears on questions about representation, explanatory relevance and the relation between raw data and intelligible structure. A learned representation may preserve the relationships that matter for prediction and explanation while discarding dimensions that are irrelevant at the effective level.
Computational models in philosophy of science
Computational methods are especially valuable in philosophy of science because scientific reasoning already relies heavily on models, simulations and idealisation. Computational philosophy can therefore investigate both scientific systems and the methods through which scientists represent them.
My work examines how machine-learning models recover higher-level scientific structure, how manifold learning relates to effective theory construction, and how accurate models can succeed despite using representations that differ substantially from those used in established scientific theories.
These questions connect computational practice to traditional philosophical problems concerning explanation, reduction, emergence, realism and understanding. A computational model may predict successfully without reproducing the underlying ontology of its target. The philosophical task is to determine what kind of epistemic achievement that success represents.
The limits of computational philosophy
Computational methods do not provide a neutral route from assumptions to truth. A simulation establishes what follows within a model, not what must occur in the world.
Several questions must therefore accompany any computational result:
- Which assumptions drive the result?
- How sensitive is it to changes in parameters or model structure?
- Which features of the target system have been deliberately omitted?
- Does the model represent a plausible mechanism, or merely reproduce an outcome?
- What kind of philosophical conclusion does the result support?
The value of computational philosophy lies partly in making these questions unavoidable. Code forces assumptions to become operational. Simulation exposes consequences that informal reasoning may overlook. Philosophical interpretation remains necessary at every stage.